
Living longer is one of humanity's oldest dreams.
And the most reliable ways to live longer are also fairly well known: exercise, sleep well, reduce stress, avoid infections, and do not lose muscle.
But if you go one step deeper, a slightly different world opens up. The question is not simply whether we can live longer, but whether we can measure aging itself, slow it down, and intervene in it.
The medical field that deals with these questions is called longevity medicine.
Medicine and biology see aging differently
The first split in any discussion of aging is the difference between the medical and biological perspectives.
In medicine, aging is a very practical problem. Can this person walk? Can they eat? Can they recover after a fall? Can they maintain daily life? This is the perspective of functional aging, or how much function is preserved. Medicine looks at human function.
Biology, by contrast, looks inside the cell. It asks how much DNA has been damaged, how disrupted the epigenetic information that controls when genes are turned on and off has become, whether mitochondria, the energy factories inside cells, are working properly, how many senescent cells have accumulated, and how much chronic inflammation has risen. Biology looks at damage and mechanisms.
Both are right.
But there is a large gap between them. Whether a person is actually living well and what kinds of damage are accumulating at the cellular level are not exactly the same thing. Someone may have biological markers that look good but still be functionally vulnerable. Conversely, someone may have poor-looking markers while showing no immediate clinical problem.
In my view, much of the confusion in longevity comes from this gap.
"Slowing aging" is easy to say, but what exactly is being slowed is less clear than it first sounds.
The causes of aging are not independent

The Hallmarks of Aging divide the causes of aging into several axes, but in real biology those axes overlap with each other.
Biologists use a framework called the Hallmarks of Aging to explain aging. It is closer to a map of the major biological signs that create aging.
It includes axes such as genomic instability, telomere attrition, epigenetic alterations, loss of proteostasis, mitochondrial dysfunction, cellular senescence, stem cell exhaustion, and chronic inflammation. When organized as a table, it looks quite clean.
The problem is that these categories are not cleanly mutually exclusive.
Cellular senescence is connected to inflammation, inflammation is connected to the immune system, and mitochondria are connected to metabolism as a whole. Changes in the regulatory information that turns genes on and off alter gene expression, or which genes are actually expressed, and gene expression changes cellular state in turn. Often, when you think you have touched one category, several others move together.
That is why attempts to reduce aging to a single number are attractive but risky. The causes are not independent, yet the complex state has to be compressed into one score.
A representative example is the epigenetic clock. This is a model that estimates biological age by looking at DNA methylation patterns, or small chemical marks attached to DNA. In theory, it is extremely attractive. Instead of reading chronological age, it reads cellular state, and it can be used to see whether a drug or lifestyle intervention slows biological age.

The biological age clock is an attractive but still cautious attempt to compress cellular state into a single number.
The problem is that there is no gold standard.
We cannot run a 50-year or 100-year clinical trial. So we apply some drug or lifestyle intervention and look at whether the epigenetic clock slowed down. But the clock itself is not perfect. If the result is ambiguous, the interpretation is ambiguous too.
Senolytics are a good example. These are drugs meant to selectively remove aged cells. The idea itself has shown interesting signals in animal models and some early human studies. But it is still difficult to answer the question, "So if a healthy person takes this, do they live longer?" The measurement tool is not yet certain, but conclusions are being drawn from the measurement.
Caloric restriction is similar.
In models such as yeast, worms, and mice, eating less often looks like a powerful intervention for increasing lifespan. But the moment you bring it to humans, the story becomes complicated. How much less should people eat? For how long? What about muscle loss or quality of life? How should we compare modern human diets with prehistoric human diets? All of these questions arrive at once.
Beautiful biology in animal models suddenly becomes messy when it reaches humans.
That is why longevity is interesting and, at the same time, always something to be careful about.
What is the most reliable answer in modern medicine?
So what is the most reliable anti-aging intervention today?
The answer is not very exciting: exercise, nutrition, sleep, infection prevention, vaccines, and maintaining muscle strength.
There are many newer and more stimulating approaches too: caloric restriction, rapamycin, metformin, NAD+ precursors, senolytics, and partial reprogramming. Partial reprogramming is an approach that tries to return only part of a cell to a younger state without fully resetting it. Each approach has interesting biological logic, and some have entered human studies.
But they are not yet at the stage where we can call them standard anti-aging therapies for healthy people in general.
At the molecular level, they may sound plausible. But applying them to humans requires evidence for efficacy, safety, long-term effects, target populations, and evaluation metrics. Results that look impressive in animal models often become vague when they cross into humans.
That does not mean they are necessarily bad for the body. It just means we still lack the measurement tools and clinical evidence needed to say, "If you do this, you will live longer."
Biology is moving onto semiconductors
This is the part I find most interesting.
Biology is increasingly moving onto semiconductors.

A virtual cell is an attempt to move biological data from the wet lab onto computable models.
Just as robotics builds simulations because you cannot knock over a real robot endlessly, biology cannot run every experiment only in a wet lab. A wet lab is a laboratory that works with real cells and reagents. Growing cells, perturbing them, and sequencing them is slow and expensive. A perturbation means shaking a cell with a gene or drug, and sequencing is the technology used to read DNA or RNA.
That is where the problem of the virtual cell appears. The idea is to build a model that imitates a cell inside a computer.
Early virtual cells were closer to connecting human-known pathways and submodels one by one. A pathway is a biological route through which something happens inside a cell, and a submodel is a piece that models only part of it. Attempts like the 2012 whole-cell model felt very futuristic at the time. But from today's machine learning perspective, there was too much human-designed structure inside.
In a sense, it is almost the opposite of the bitter lesson. The bitter lesson is the machine learning lesson that large data and large computation ultimately won over carefully hand-crafted human rules.
Recent approaches have moved toward foundation models. A foundation model is a model trained first on large-scale data, whose representations are then reused for many downstream tasks.
With single-cell RNA sequencing, each cell becomes a gene expression vector with tens of thousands of dimensions. It reads which genes are expressed in a single cell and turns those values into an array of numbers. Models like scGPT treat this vector like a sentence and train it with a transformer. The resulting embedding, or compressed numerical representation of cellular state, is then used for downstream tasks such as cell type annotation or perturbation prediction.
In other words, cells are being treated like language.
Biological multimodal LLMs are also joining this direction. These are LLMs that read different forms of information together, such as DNA and text. For example, a dedicated encoder reads a DNA sequence, its embedding is fed into an LLM, and the model reasons about how a variant, or genetic mutation, may be connected to disease.
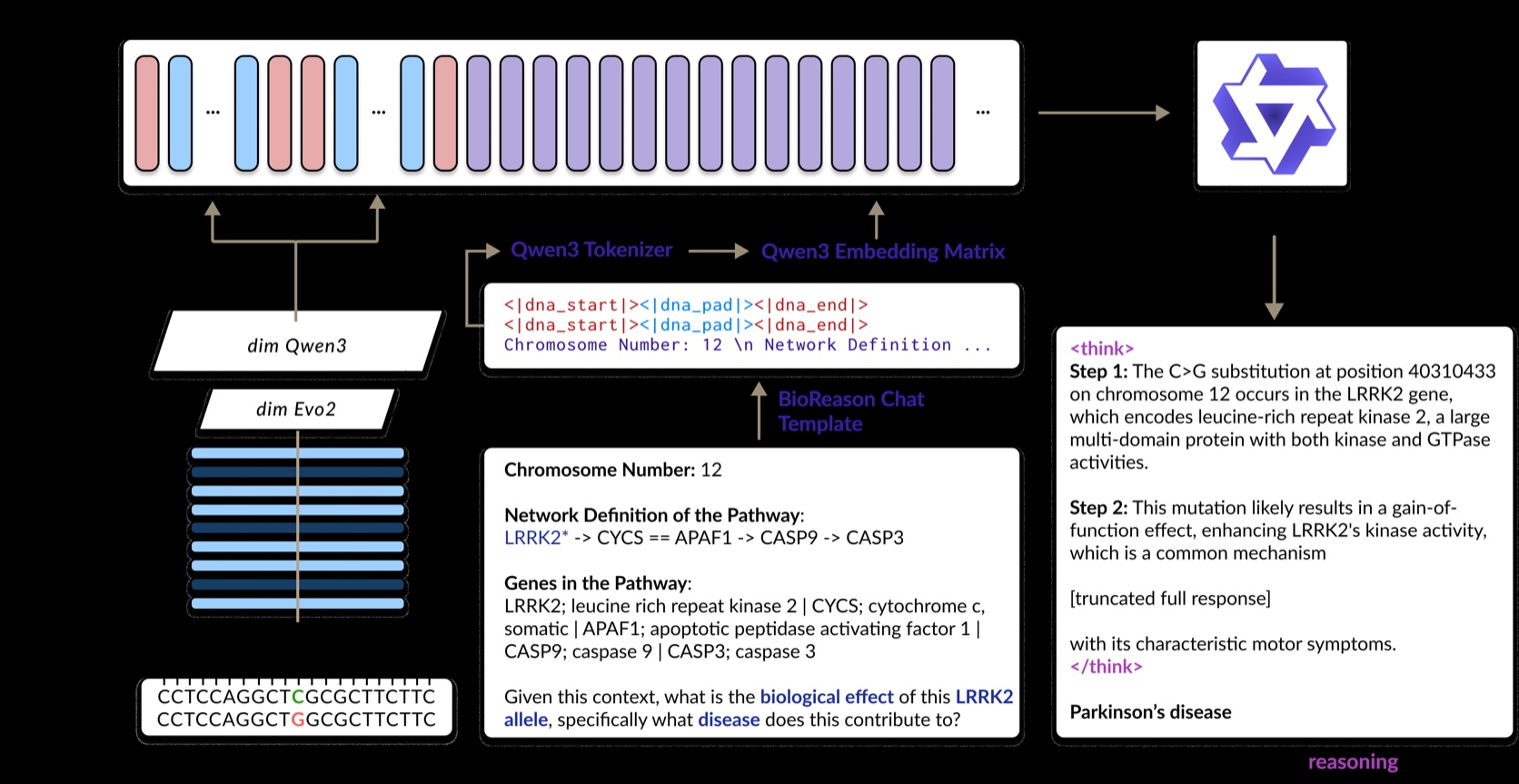
If DNA sequences are converted into representations that an LLM can understand, a new form of biological reasoning about the relationship between variants and disease becomes possible.
I like this direction.
Part of it is that I trust LLMs quite a bit, but more fundamentally, biology has too many human-made assays and analysis methods. An assay is an experimental method for measuring a cell or molecule in a specific way. There are separate ways to look at DNA, RNA, proteins, gene regulation, individual cells, and spatial information inside tissue, and each layer has its own experts. There are humans who are good at each one. But there are very few humans who understand all of those layers well at the same time.
The role of LLM-based models may be to connect many measurement layers and many experts' knowledge inside one model.
A tool for reducing questions, not for getting the answer right
Of course, virtual cells have major risks.
If we put in all the data, can we really predict a cell's phenotype? A phenotype is the cellular state or behavior that eventually appears from genetic or molecular information. Is that a problem humans could solve if given enough time and information? Or is there still too much information that humans do not know?
Honestly, I still do not know.
I think that is the biggest risk in this field. The problem itself is not yet well defined. If we gave someone every type of measurable data for a cell or tissue, I am not even sure humans could perfectly understand it. Humans have rarely actually performed that task.
So where can virtual cells be useful?
The realistic value of a virtual cell may be in reducing the search space rather than finding the answer all at once.
The realistic answer is reducing the set of candidates. It is difficult for a virtual cell to produce the correct answer in one shot. A score without wet lab validation, meaning validation through real experiments, always feels uncomfortable. Even with AlphaFold-like models, a high-scoring structure is not immediately biologically correct.
But if a million drug candidates can be reduced to ten thousand, the story changes. If we can predict whether a particular perturbation will meaningfully change cellular state, the experimental search space itself becomes smaller.
It is closer to a tool for reducing questions than a tool for getting the answer right.
That is why it is interesting that places like Noetik, Recursion, Arc Institute, and the Chan Zuckerberg Initiative are moving in this direction. The fact that Noetik licensed its virtual cell model to GSK sent the field a signal that "this can make money." Of course, there still are not many players who have actually made large amounts of money from it. That makes it even more interesting.
The next chapter of longevity
I do not think longevity is a field that can currently answer the question, "What should I eat to live longer?"
The biological age clock is an interesting metric, but it is not clinical truth itself. Immune age is also not yet a number that can represent the whole immune system. A virtual cell also cannot complete the loop without wet lab validation.
Even so, I think this field matters because it is gradually turning biology into a computable problem.
Until now, aging and immunity were mostly objects of retrospective observation. We looked at what changes occur with age, or which markers change after a disease appears. But now we can read layers such as DNA methylation, RNA expression, proteins, antibody diversity, metabolites, and spatial information inside tissue in much finer detail.
Once we can read enough, the next step is choosing better interventions to try.
Aging is not yet solved by a single number. Immunity is the same. But both are becoming increasingly readable. And once something becomes readable enough, humans will eventually try to write to it.
From that point on, longevity becomes not a problem of health management, but a problem of programmable biology.