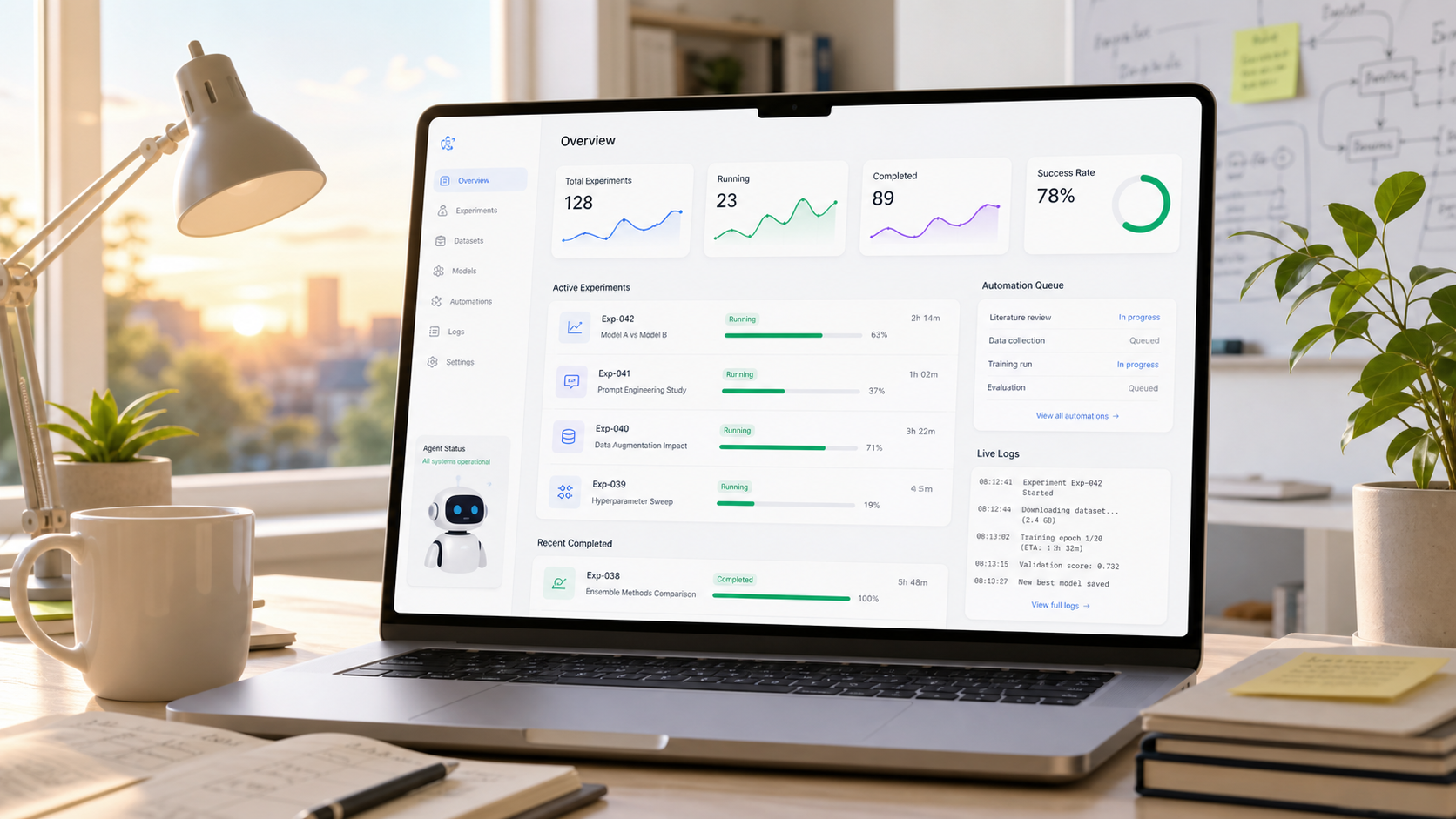
Research work is shifting from manually touching notebooks toward reading and steering dashboards that agents keep updating.
The way I use AI is changing fast.
I used to write code by hand, run notebook cells one by one, look at the output, edit, and repeat. But over the past few months I keep noticing that this whole format is quietly aging. It feels even more dated once you start working alongside AI agents. Jupyter notebooks — a format built around a human poking at things by hand — don't fit well with an agent that runs long loops, experiments on its own, and leaves a trail of results. My guess is that going forward, an agent-updated dashboard will be a far more natural workspace than a notebook.
That's increasingly how I work.
Instead of touching code directly, I let the agent run experiments, organize the results, and surface them as a web dashboard. I look at the dashboard and intervene with things like "add this metric too," "this looks off — slice it differently and re-analyze," or "PnL alone is boring, show me exit quality alongside it." The role has shifted: I'm no longer the hands and feet of every experiment. The agent runs the experiments, and I steer the research direction.
The most interesting thing in this shift, for me, has been autoresearch.
autoresearch is, at its core, an attempt to automate the research loop
The core idea of autoresearch is simple.
Instead of asking AI to run code once, you turn the research itself into a loop and keep it running. There's an objective. There are experiments. There are things you can change and things you can't. Set those rules, and the agent runs experiments, logs results, and moves toward the next experiment in a better direction. In effect, the "think — experiment — log — revise" cycle a researcher used to run gets handed off, at least partially, to AI.
What makes this interesting isn't hyperparameter tuning. Hyperparameter search has existed for ages. The interesting part of autoresearch is that it isn't just tweaking numbers — it's gradually shifting the research strategy itself, and closing the loop on top of that. Change a setting, try a method, keep what works, drop what doesn't. Any researcher already does this. What's new is that an LLM can orchestrate it.

The core of autoresearch is not one execution, but closing the think-experiment-log-revise loop.
I find this idea pretty convincing. On the question of "can you actually put AI to work all day on research?", a partial answer is already in: yes, inside a well-designed loop. The catch is the phrase "well-designed."
I applied this to trading strategy research, not to model training
I didn't copy the standard recipe — I adapted it to the problem I was already working on.
What I deal with is the output of a model that predicts how much the market will rise or fall, and what actually matters more is how you turn that prediction into a trading strategy. Whether the model is accurate matters less than the logic you use to execute and exit on top of its inferences. That logic often has a much bigger impact on real returns.
So I fixed two things. One: the existing inference output — the prediction of market direction. Two: the backtest engine.
The reason is simple. I didn't want the agent to improve performance by poking the wrong things. If you let it touch the backtest engine, it might lower fees to unrealistic levels, twist the evaluation in its favor, or otherwise discover "shortcut optimizations" I never wanted. That isn't research — it's metric gaming. So engine and data stay fixed, and only the strategy logic, parameters, and research rules are open to change.

Loop design is largely the work of deciding what the agent may change, and what it must never touch.
With that constraint, autoresearch goes to work. The agent changes strategies, runs experiments, runs backtests, organizes results, and tries something better. I watch the dashboard and intervene again. The structure isn't really full automation — it's more like a human laying direction on top of an automatic loop, over and over.
It isn't a fully autonomous researcher yet
This leads to an important conclusion.
Autoresearch is fun, and genuinely useful. But it isn't yet at a level you'd call a fully autonomous researcher.
The biggest issue is depth of thought. The agent runs the loop well. It tries a lot, leaves logs, organizes results. It can grind through the night without rest. But after a while there's a clear sense that it's stuck inside a particular pattern of thinking. Shallow exploration is a strength — local search like nudging hyperparameters, tweaking metrics, or adjusting exit conditions goes pretty well. But the genuinely important insights — "why is this strategy structurally breaking," "which assumption do I need to throw out," "is the entire search space wrong?" — it still struggles to get into.
You feel this almost immediately when you actually use it. At first it seems like you can just close the loop and the system will keep improving on its own. But after some point, if a human doesn't inject insight, it just circles the same neighborhood. So the setup I find most useful right now isn't full automation — it's the agent running experiments while I inject interpretation and direction along the way.
In other words, autoresearch isn't yet "replacing the researcher." It's closer to a system that takes the researcher's night shift.
The lever isn't the model — it's the loop design
What's hit me harder while running this in practice is that a large share of performance comes not from the model, but from how the loop is designed.
What do you fix? What do you let it change? Which metrics does it look at? When does it stop? Which experiments are off-limits?
These details matter much more than they look. A loose loop sends the agent in odd directions fast. Give it too much freedom and it starts rewriting the objective, reordering priorities, or finding the very shortcuts you tried to block. Wrap it too tight and it becomes no different from a mechanical search tool. What matters in the end isn't AI's "intelligence" — it's the orchestration choice of where to put research's freedom and where to put its constraints.
I think this is the real essence of autoresearch. From the outside, "AI doing research" sounds impressive. In practice, it's no exaggeration to say that the loop you build and the evaluation structure you put inside it are nearly the whole game.
In trading, the reality gap shows up sharply
Apply this to trading and another problem becomes very visible: a backtest is, after all, a test on past data.
A strategy can look good in backtest and underperform in the real market. Obvious enough. But the more you optimize a strategy with an agent attached, the more sensitive it becomes. Bump the trading fee up just a little and the strategy can collapse. Markets are more efficient than you'd think, and the small edges you saw in backtest evaporate easily under real-world friction. So in practice, exit often matters more than entry, and execution quality often matters more than headline returns.
The small edge that appears in a backtest can quickly disappear against real-world friction: fees, slippage, and execution quality.
This is where autoresearch earns its keep. Instead of letting it stare at PnL alone, you can keep adding the realistic metrics you care about: fee sensitivity, how exits break, whether the strategy depends on a specific regime. Then the agent drifts not toward "a money-making strategy" but toward strategies that can hold up against reality at least somewhat.
There are limits, of course. The sim-to-real gap in markets is large. A backtest looks at the past; the real market is always messier. So the more honest framing is that autoresearch doesn't directly make you money — it lets you explore strategies faster and discard them faster.
Today's autoresearch is closer to "an IQ-115 colleague"
If I had to describe it precisely, I'd put it like this.
Autoresearch isn't a genius researcher. It also isn't a dumb automation script. It's closer to an IQ-115 colleague who works through the night without rest.

Today’s autoresearch feels less like a replacement researcher and more like a tireless night-shift colleague.
It's pretty good at shallow, broad exploration. It tabulates metrics, repeats experiments, visualizes comparisons, and pushes through the kind of repetitive work humans get bored doing. What it isn't good at — yet — is the deep idea-jump, the invention of a genuinely new hypothesis, or the kind of insight that breaks an existing frame. Humans still have the edge there.
So I find it more accurate to think of it not as a system that replaces researchers, but as an assistant and executor that amplifies a researcher's thinking.
By day I set the direction. By night the agent runs dozens of experiments along that direction. In the morning I look at the results and decide again.
This workflow is already useful. And much of knowledge work is probably going to reshape itself into this same form.
What's really shifting isn't AI itself — it's the boundary of work you can hand to AI
The biggest shift I felt while using autoresearch isn't that AI suddenly got smarter than humans.
It's that the range of research labor a human no longer has to do directly has gotten meaningfully wider.
The person designing the experiment and the person running the experiment used to be the same person. Now you can split the two. Humans set direction and standards; AI runs the loop, leaves logs, organizes results, and stages the next attempt. That this structure is even possible is itself a fairly large change.
So the meaning of autoresearch, to me, isn't that "AI becomes a researcher." It's that research itself is increasingly becoming an orchestration problem. Good researchers may end up being not the people who run every experiment by hand, but the people who decide which problem to close in which loop, what to fix, and what to let the system explore.
We still need human intervention. Depth of thought is still missing. But as an executor that runs through the night, an experimental partner that doesn't tire of repetition, and a system that organizes results into raw material for the next decision — it's already useful enough.
A fully autonomous researcher is still far away. But the partially automated research loop has already started. The important thing is to understand that distinction precisely and use it accordingly.